Note that some people do not classify this kind of file system as log-structured (see Free Space Management); e.g., Valerie Henson classifies such file systems as copy-on-write file systems. However, throughout this page the term "log-structured" is used.
But if an application requires that files or groups of files are internally consistent, this cavalier attitude to data consistency is not satisfactory. Some people say that the application should use fsync() to ensure consistency, but even if the application programmers try to follow this advice, they find that it is hard to test, because it can only be fully tested by pulling the plug on the machine. And if a feature is hard to test and rarely used, it will often have bugs.
The consistency guarantee we wish for is in-order semantics: the state of the file system after recovery represents all write()s (or other changes) that occurred before a specific point in time, and no write() (or other change) that occurred afterwards. I.e., at most you lose a minute or so of work (and you can eliminate that with fsync()/sync() when needed). This means that if an application ensures file data consistency in case of its own unexpected termination by performing writes and other file changes in the right order, its file data will also be consistent (but possibly not up-to-date) in case of a system failure. Consistency through unexpected termination is much easier to test than consistency through a system crash, so it is much more likely that programmers will get it right.
Most file systems today do not give the in-order semantics guarantee. In general they give hardly any guarantee about data consistency, just about metadata consistency. This includes most journaling file systems (most of them offer just meta-data journaling from the start, and in ext3, which used to offer data journaling, this feature is broken in many Linux versions); and those that offer it, suffer a substantial performance penalty, as all data has to be written twice.
Reiser4 uses LFS techniques (called Wandering Logs in Reiser4) and other techniques to achieve very good consistency guarantees (it allows full transactions via file system plugins), although it's not completely clear if it gives the in-order semantics consistency guarantee. However, Reiser4 does not offer snapshots or clones (yet:-). It is also a much more complex file system, and thus probably less amenable to studying variations in the design decisions.
Creating a snapshot of a file system is very useful for making consistent backups of the file system without disabling read access to it. They also allow access to files that have been deleted or changed in the mainline.
LVMs offer snapshot functionality somewhat independently of the file system (some interaction is required to ensure that the snapshot is of a consistent file system). The disadvantage of an LVM is that it is less efficient in:
However, the write performance of file systems like ext2 is so good that it is probably hard to beat, and not by much; for most uses, write performance is not a big issue. The main contributions to write performance over BSD FFS have been completely asynchronous operations and improved block allocation policies.
Therefore, wrt performance the goal of the present project is just to stay competetive with file systems like ext2 and ext3 on typical workloads (and maybe exceptionally good or bad on artificial workloads). As a consequence, some of the design decisions in the present project are quite different from those set out in early LFS work.
To understand the following, you will probably find it helpful to read the first three sections of LinLogFS - A Log-Structured Filesystem For Linux first.
I propose going back to the free-blocks set, for the following reasons:
Reference counting incurs the following costs: Clone creation is cheap. Writing to a block with a count >1 may be more expensive by a constant factor than writing a plain block; the worst case is if a fully-used indirect block is written to; then the reference counts of all pointed-to blocks have to be updated (e.g., 1024 for a 4KB indirect block with 4-byte block numbers). Clone deletion cost is proportional to the number of blocks unique to the clone. These costs seem acceptable.
An alternative is to allocate several extents (block ranges) distributed on the disk for commit points and record these extents in the superblock(s). Then we can use these extents for many commit points before having to update the superblocks again.
By using several extents distributed across the disk, we can write a commit block close to the data and meta-data of the files described in the commit block, limiting the seek time during writing.
One advantage of this approach is that we can read lots of commit points with a few seeks, requiring relatively rare roll-forward start points; however, to take full advantage of this requires organizing the on-disk information (especially the change records) and the in-memory data structures in a way that does not require many seeks on mounting.
To ensure that we recognize only commit points as commit points, the file system has to clear the extent before using it for commit points. Time stamps in the commit points are used to determine their order.
So, overall the order of operations is:
clear an extent of blocks, allocate them for commit points commit update the superblocks start writing commit points to the extentOf course, at some point the FS has to free an extent (to allow adding a new one to the superblock). This can be achieved by either producing a roll-forward start block (this frees several commit point extents), or by consolidating commit information from that extent into the other extents in some other way (this is probably not worth doing).
One variation on this idea would be to allocate and clear extents for commit blocks on file system creation, and never change the location of these extents, making writes to the superblock and later clearing of the extent unnecessary. In this variant only freeing of individual commit blocks (instead of whole extents) would be necessary. Problem: How to deal with bad blocks (if at all)?
This is especially cheap when the file system has just read the file, as the contents are still in the cache; this is also the time when we notice without additional effort that the file is fragmented.
As a special case of this kind of defragmentation, an overwritten block of an existing file may be written back to the place where the original block resided, if that block is now free. This is somewhat similar to how journaling file systems work.
Snapshots and clones present a special problem in that context: They will be used for making backups, and most fragmeted files will probably be noticed during backup; So the file system wants to defragment in the snapshot/clone. If done so, this would inhibit defragmentation in the user-side snapshot/clone. How do we make the defragmentation affect all heads?
So the following are some ideas for how to make such a set-per-clone approach workable in a more general setting than WAFL. They might be useful if you need to know which clones a block belongs to, how many blocks a clone would occupy by itself, etc. But as long as you don't know you need this, this is probably not worth reading.
At each snapshot we have a set of free blocks (and complementary, a set of allocated blocks) for the files reachable through this snapshot. The free block set for the whole file system is the intersection of the free block sets of all the snapshots (including the head of the file system).
How do we get this global free-blocks set when we need it (in particular, for allocating blocks for a file)? We maintain it all the time, and update it when something changes. The changes that are of interest are:
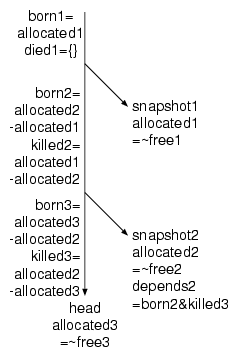
As long as we have only read-only snapshots, we can view the file system as a linear sequence of snapshots. Between two snapshots, a set of blocks are allocated (born), and a set of blocks are freed (killed). The FS maintains the set of blocks that were born and killed since the last snapshot. This leads to the following maintenance actions:
free &= ~{block}
head.born |= {block}
if (block in head.born)
head.born &= ~{block}
free |= {block}
else
head.killed |= {block}
snapshot.born=head.born
snapshot.killed=head.killed
head.born = {}
head.killed = {}
free |= snapshot.born & snapshot.next.killed snapshot.next.born |= snapshot.born &~ snapshot.next.killed snapshot.next.killed &= ~snapshot.born snapshot.next.killed |= snapshot.killed
So, overall, maintaining the free list across all snapshots is relatively simple, allocating and freeing blocks in the head cost not much more than in the simple case, creating a snapshot is cheap, and the cost of destroying a snapshot depends on how much allocation/freeing happened between the adjacent snapshots, which should be acceptable.
Some invariants for all snapshots (including head):
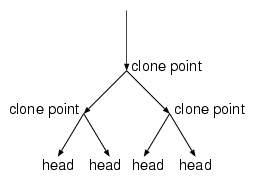
The invariants above change; in particular, the killed sets of alternative edges can overlap (the same block can be freed in several alternative clones).
The relevant file system operations now are:
free &= ~{block}
head.born |= {block}
if (block in head.born)
head.born &= ~{block}
free |= {block}
else
head.killed |= {block}
if (block in all head.killed)
free |= {block}
all head.killed &= ~{block} /* necessary? correct? */
clonepoint.born=head.born
clonepoint.killed=head.killed
head1.born = {}
head1.killed = {}
head2.born = {}
head2.killed = {}
free |= head.born | (clonepoint.born & brother.killed) brother.born |= clonepoint.born &~ brother.killed brother.killed &= ~clonepoint.born brother.killed |= clonepoint.killed
The operations to perform are as outlined above; in addition, there has to be a way to quickly find a mostly-contiguous set of blocks (this is probably already solved well in current file systems that are based on free-block sets).
The representations of sets with few elements should be relatively small, and set operations involving few elements on one or both sides should be relatively cheap. Also, reading partial/incremental sets from commit points during mounting should not require many seeks to complete the mount (either by having a data structure that does not require much seeking, or by performing the seeking lazily after mounting).
Probably some tree-based set implementation is a good idea for the on-disk data structure, with incremental change records for commit points; for most in-memory sets (which will probably be relatively small compared to the number of total blocks), such a tree will probably be a good idea, too.