![Syntaxbaum fü a[2]](g2-a.gif)
Gegeben sei folgende Grammatik, die aus verschachtelten indizierten Variablen aufgebaute Ausdrücke beschreibt:
S -> E E -> id [ L ] | num L -> L "," E | E
Erweitern Sie diese oder eine äquivalente Grammatik zu einer
attributierten Grammatik, die die Übersetzung der Ausdrücke in
Quadrupelcode beschreibt, der den Wert des Ausdrucks berechnet. Der
Quadrupelcode soll im synthetisierten Attribut S.code
generiert werden. Das Attribut num.val enthält den numerischen
Wert der Zahl, id.sym den Namen der Arrayvariable. Zur
Bestimmung der Anzahl der Elemente der i-ten Dimension eines Arrays
sym steht die Funktion dim(sym, i) zur Verfügung. Die
Funktion newtemp liefert eine neu erzeugte Hilfsvariable
zurück.
Anmerkung: Die Basistypen der Arrays die mit dieser Grammatik bearbeitet werden sollen sind alle 4 Bytes groß.
S -> E S.code := E.c
E -> id [ L ] L.sym := id.sym
t0 := newtemp
t1 := newtemp
E.v := newtemp
E.c := L.c
|| gen( t0 ':=' L.v '*' 4 )
|| gen( t1 ':=' t0 '+adr(' id.sym ')' )
|| gen( E.v ':=' '@' t1 )
E -> num E.v := num.val
E.c := ''
L -> L1 "," E L1.sym := L.sym
L.i := L1.i + 1
t1 := newtemp
L.v := newtemp
L.c := L1.c
|| E.c
|| gen( t1 ':=' L1.v '*' dim( L.sym, L.i ) )
|| gen( L.v ':=' t1 '+' E.v )
L -> E L.i := 1
L.v := E.v
L.c := E.c
Erklärungen von attributierten Grammatiken sind immer schwierig, weil es beliebig viele Möglichkeiten gibt, eine Grammatik zu attributieren. In diesem Zusammenhang verweise ich zuallererst auf den Appendix des letzten Skriptums.
Was ist eigentlich zu tun? Wo liegt das (eigentliche) Problem?
Es macht einen großen Unterschied aus, ob man eine bestehende Grammatik attributieren oder eine ganz neue Grammatik erstellen soll. Im ersten Fall muß man unbedingt das Gesamtkonzept erfassen und die Intention der Grammatik begreifen.
Die zu lösenden Fragen sind folgende:
Die beste Methode eine Grammatik zu attributieren ist wahrscheinlich, sich die Syntaxbäume aufzuzeichnen. Dann sieht man relativ leicht die Stellen wo Attribute verwendet werden.
Nehmen wir einmal an, wir wollen Code für den Zugriff auf
a[2]
erzeugen. Der zugehörige Syntaxbaum sieht so aus:
Von vorher kennen wir schon die Quadrupelfolge für so einen Zugriff. Diese ist
t0 := 2 * 4 t1 := t0 + adr(a) t2 := @t1
Das ist ja noch relativ einfach. Der Index (in diesem Fall 2) wird mit der Anzahl der Speichereinheiten für ein Element (4 Bytes) multipliziert und die Basisadresse addiert. Der Zugriff auf ein zweidimensionales Array ist da schon interessanter.
a[2,5]
ergibt
Die Quadrupelfolge ist
t0 := 2 * dim(a,2) <- Anzahl der Elemente der zweiten Dimension von Array a t1 := t0 + 5 t2 := t1 * 4 t3 := t2 + adr(a) t4 := @t3
Hier brauchen wir zusätzlich die Größe der zweiten
Dimension des Arrays, deshalb der Zugriff mittels dim(a,2).
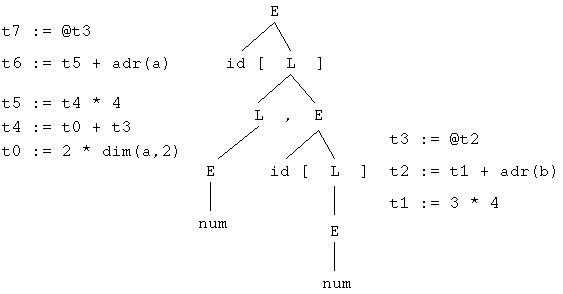
Der Vollständigkeit halber auch noch der Syntaxbaum für den komplexeren Zugriff
a[2,b[3]]
ergibt
Dabei sehen wir etwas sehr interessantes: Dieser Syntaxbaum ist nur
eine Zusammensetzung aus den beiden oberen. Wir müssen also
offensichtlich nur sicherstellen, daß bei E ein
numerischer Wert erzeugt wird weil dieser für die nächste
Indexberechnung gebraucht wird. Die erzeugte Quadrupelfolge zeigt das deutlich.
t0 := 2 * dim(a,2) <- Anzahl der Elemente der zweiten Dimension von Array a t1 := 3 * 4 t2 := t1 + adr(b) t3 := @t2 <- hier steht das Ergebnis von b[3] t4 := t0 + t3 t5 := t4 * 4 t6 := t5 + adr(a) t7 := @t6
Dieser Code wird im Syntaxbaum ungefähr an diesen Stellen erzeugt:
Die Berechnung des Index erfolgt also irgendwo in der Produktion
L und die endgültige Adresse wird in E
berechnet.
Wo beginnt man? Einfach dort, wo es einem einfällt. Zum Beispiel bei der Produktion
E -> id [ L ]
Hier soll ja die endgültige Adresse berechnet werden. Was brauchen wir dazu?
id
L
Das ist gut, denn beide Werte haben wir. Der Name der Variable steht
in id.sym und vom Wert der Indexvariablen nehmen wir an,
daß er in einem synthetisierten Attribut L.v
geliefert wird.
NB: Für die einfache AbleitungL->E->numkönnen wir gleich die entsprechenden Attributierungsregeln hinschreiben, alsoE -> num E.v := num.val L -> E L.v := E.vDen komplizierteren Fall behandeln wir weiter unten.
Die zu generierende Quadrupelfolge sieht so aus (siehe erster Syntaxbaum)
t0 := L.v * 4 t1 := t0 + adr(id.sym) t2 := @t1
Wir brauchen also insgesamt drei neue Variablen. Daraus ergeben sich die folgenden Attributierungsregeln:
E -> id [ L ] t0 := newtemp <- neue Variablen erzeugen
t1 := newtemp
E.v := newtemp <- hier kommt das Ergebnis hinein
E.c := L.c <- das ist der Code der vorher erzeugt wird
|| gen( t0 ':=' L.v '*' 4 )
|| gen( t1 ':=' t0 '+adr(' id.sym ')' )
|| gen( E.v ':=' '@' t1 )
Wir haben hier stillschweigend angenommen, daß in
L.c der Code steht, der weiter unten im Syntaxbaum
erzeugt wurde. Weiters haben wir uns hier auf das Attribut
c für den generierten Code festgelegt (wir sind
schreibfaul, c ist kürzer als
code). Daraus ergeben sich sofort die folgenden Durchreicheregeln:
S -> E S.code := E.c <- Das Ergebnis soll ja in S.code stehen E -> num E.c := '' <- hier wird gar nichts erzeugt L -> E L.c := E.c <- Durchreicheregel
Nach dem Studium des Syntaxbaums und des erzeugten Codes wissen wir, welchen Code wir zusätzlich erzeugen müssen.
t0 := L.v * dim(L.sym,?) <- hier kommt die Anzahl der Elemente hinein t1 := t0 + E.v <- das Ergebnis des anderen Teilbaums
Mehr müssen wir nicht erzeugen. Alles weitere haben wir schon beim eindimensionalen Zugriff erledigt, insbesondere die Berechnung der Adresse und den Zugriff auf eine Zelle des Arrays.
Einzig die Dimension des Arrays müssen wir noch
feststellen. Bei der Ableitung E -> id[L] und L
-> E ist's ja noch einfach: Die Stelligkeit der Dimension
ist 1 und wird außerdem nicht weiter verwendet. Erst bei L
-> L1 "," E brauchen wir die Stelligkeit von L1. Also fangen
wir mit
L -> E L.i := 1
an und zählen von dort aus weiter, also
L -> L1 "," E L.i := L1.i + 1
Für den Zugriff auf die i-te Dimension können wir dann
gleich den Wert von L.i verwenden. Die kompletten
Produktionen sind dann
L -> L1 "," E L.i := L1.i + 1
t1 := newtemp <- neue Variable erzeugen
L.v := newtemp <- Platz für das Ergebnis
L.c := L1.c <- Code von vorher
|| E.c <- noch mehr Code von vorher
|| gen(t1 ':=' L1.v '*' dim(L.sym,L.i))
|| gen(L.v ':=' t1 '+' E.v)
Nach dem Zusammensetzen der einzelnen Bausteine und dem Hinzufügen der Durchreicheregeln erhalten wir die endgültige Lösung.
![Syntaxbaum für a[2,5]](g2-a2.gif)
![Syntaxbaum für a[2,b[3]]](g2-ab.gif)