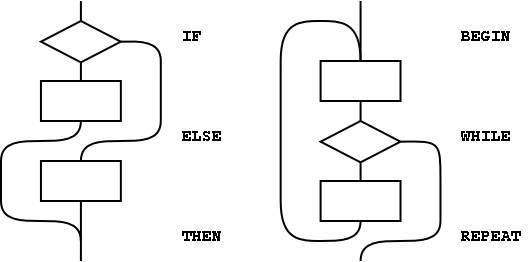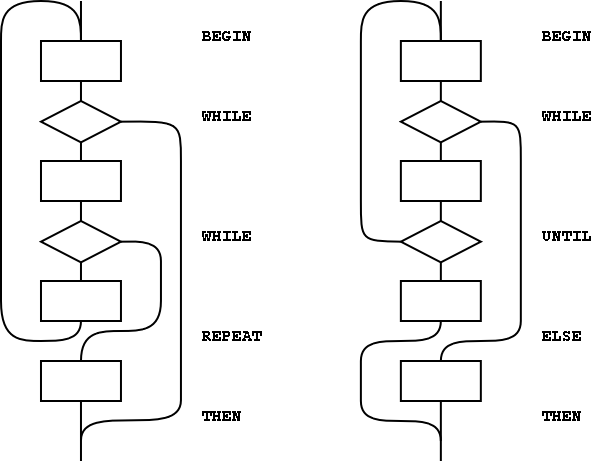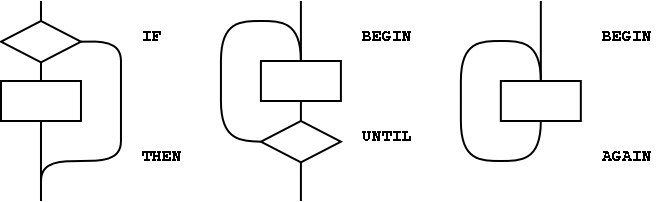
Figure A.1: The basic control-flow patterns
| Consistency | The standard provides a functionally complete set of words with minimal functional overlap. |
| Cost of compliance | This goal includes such issues as common practice, how much existing code would be broken by the proposed change, and the amount of effort required to bring existing applications and systems into conformity with the standard. |
| Efficiency | Execution speed, memory compactness. |
| Portability | Words chosen for inclusion should be free of system-dependent features. |
| Readability | Forth definition names should clearly delineate their behavior. That behavior should have an apparent simplicity which supports rapid understanding. Forth should be easily taught and support readily maintained code. |
| Utility | Be judged to have sufficiently essential functionality and frequency of use to be deemed suitable for inclusion. |
xx C!
xx C@" must leave a stack item with some
number of bits set, which will thus will be accepted as
non-zero by IF.
) WORD"
may collect a string containing control characters.
| Arithmetic architecture | signed numbers | unsigned numbers | |||||
| Two's complement | -n-1 | to | n | 0 | to | 2n+1 | |
| One's complement | -n | to | n | 0 | to | n | |
| Signed magnitude | -n | to | n | 0 | to | n | |
| two's complement: | : NEGATE INVERT 1+ ; |
| one's complement: | : NEGATE INVERT ; |
| signed-magnitude: | : NEGATE HIGH-BIT XOR ;
|
HIGH-BIT is a bit mask with only the most-significant
bit set. Note that all of these number systems agree on the
representation of non-negative numbers.
Per 3.2.1.1 Internal number representation and
6.1.0270 0=, the implementor must ensure that no standard or
supported word return negative zero for any numeric (non-Boolean or
flag) result. Many existing programmer assumptions will be violated
otherwise.
There is no requirement to implement circular unsigned arithmetic,
nor to set the range of unsigned numbers to the full size of a cell.
There is historical precedent for limiting the range of u to
that of +n, which is permissible when the cell size is greater
than 16 bits.
1 2 - underflows if the result is
unsigned and produces the valid signed result -1.
| at compile-time, | |||
| word: | supplies: | resolves: | is used to: |
| IF | orig | mark origin of forward conditional branch | |
| THEN | orig | resolve IF or AHEAD | |
| BEGIN | dest | mark backward destination | |
| AGAIN | dest | resolve with backward unconditional branch | |
| UNTIL | dest | resolve with backward conditional branch | |
| AHEAD | orig | mark origin of forward unconditional branch | |
| CS-PICK | copy item on control-flow stack | ||
| CS-ROLL | reorder items on control-flow stack | ||
WHILEs because REPEAT resolves one THEN. As
above, if the user finds this count mismatch undesirable, REPEAT
could be replaced in-line by its own definition.
Other loop-exit control-flow words, and even other loops, can be
defined. The only requirements are that the control-flow stack is
properly maintained and manipulated.
The simple implementation of the CASE structure
below is an example of control structure extension. Note the
maintenance of the data stack to prevent interference with the
possible control-flow stack usage.
1 CHARS. Similarly, alignment may be
determined by phrases such as 1 ALIGNED.
The environmental queries are divided into two groups: those that
always produce the same value and those that might not. The former
groups include entries such as MAX-N. This information is
fixed by the hardware or by the design of the Forth system; a user
is guaranteed that asking the question once is sufficient.
The other, now obsolescent, group of queries are for things that may
legitimately change over time. For example an application might test
for the presence of the Double Number word set using an environment
query. If it is missing, the system could invoke a system-dependent
process to load the word set. The system is permitted to change
ENVIRONMENT?'s database so that subsequent queries about
it indicate that it is present.
Note that a query that returns an "unknown" response could produce
a "known" result on a subsequent query.
TABLE. In
accessing this table,
TABLE C@ | will return 1 |
TABLE CHAR+ C@ | will return 2 |
TABLE 2 CHARS +
ALIGNED @ | will return 1000 |
TABLE 2 CHARS +
ALIGNED CELL+ @ | will return 2000. |
-1 to
represent all bits set without significantly restricting the
portability of the program.
Because all programs require space for data and instructions, and
time to execute those instructions, they depend on the presence of
an environment providing those resources. It is impossible to predict
how little of some of these resources (e.g. stack space) might be
necessary to perform some task, so this standard does not do so.
On the other hand, as a program requires increasing levels of
resources, there will probably be sucessively fewer systems on
which it will execute sucessfully. An algorithm requiring an array
of 109 cells might run on fewer computers than one requiring
only 103.
Since there is also no way of knowing what minimum level of resources
will be implemented in a system useful for at least some tasks, any
program performing real work labeled simply
a "Standard Forth-2012 Program" is unlikely to be labeled
correctly.
) ...
X ...
." ccc" ...
;
An implementation may define interpretation semantics for
." if desired. In one plausible implementation,
interpreting ." would display the delimited message.
In another plausible implementation, interpreting ."
would compile code to display the message later. In still
another plausible implementation, interpreting ." would
be treated as an exception. Given this variation a Standard
Program may not use ." while interpreting. Similarly,
a Standard Program may not compile POSTPONE ."
inside a new word, and then use that word while interpreting.
X ... DOES> ... ;
Following DOES>, a Standard Program may not make any
assumptions regarding the ability to find either the name of
the definition containing the DOES> or any previous
definition whose name may be concealed by it. DOES>
effectively ends one definition and begins another as far as
local variables and control-flow structures are concerned.
The compilation behavior makes it clear that the user is not
entitled to place DOES> inside any control-flow
structures.
JSR reference.
NOT was originally provided in Forth as a
flag operator to make control structures readable. Under its
intended usage the following two definitions would produce
identical results:
NOT as a cell-wide one's-complement
operation, functionally equivalent to the phrase -1
XOR. At the same time, the data type manipulated by
this word was changed from a flag to a cell-wide collection of
bits and the standard value for true was changed from "1"
(rightmost bit only set) to "-1" (all bits set). As these
definitions of TRUE and NOT were incompatible
with their previous definitions, many Forth users continue to
rely on the old definitions. Hence both versions are in common
use.
Therefore, usage of NOT cannot be standardized at
this time. The two traditional meanings of NOT —
that of negating the sense of a flag and that of doing a one's
complement operation — are made available by 0= and
INVERT, respectively.
ENDIF
POSTPONE THEN
; IMMEDIATE
: X ...
IF ... ENDIF
... ;
POSTPONE replaces most of the functionality of
COMPILE and [COMPILE]. COMPILE and
[COMPILE] are used for the same purpose: postpone the
compilation behavior of the next word in the parse area.
COMPILE was designed to be applied to non-immediate
words and [COMPILE] to immediate words. This burdens
the programmer with needing to know which words in a system
are immediate. Consequently, Forth standards have had to
specify the immediacy or non-immediacy of all words covered by
the standard. This unnecessarily constrains implementors.
A second problem with COMPILE is that some
programmers have come to expect and exploit a particular
implementation, namely:
: COMPILE R>
DUP @ , CELL+ >R
;
This implementation will not work on native code Forth systems.
In a native code Forth using inline code expansion and peephole
optimization, the size of the object code produced varies; this
information is difficult to communicate to a "dumb"
COMPILE. A "smart" (i.e., immediate) COMPILE
would not have this problem, but this was forbidden in previous
standards.
For these reasons, COMPILE has not been included in
the standard and [COMPILE] has been moved in favor of
POSTPONE. Additional discussion can be found in Hayes,
J.R., "Postpone", Proceedings of the 1989 Rochester
Forth Conference.
X ... RECURSE ... ;
This is Forth's recursion operator; in some implementations it
is called MYSELF. The usual example is the coding of
the factorial function.
n2 = n1(n1-1)(n1-2)...(2)(1), the product of n1
with all positive integers less than itself (as a special case,
zero factorial equals one). While beloved of computer scientists,
recursion makes unusually heavy use of both stacks and should
therefore be used with caution. See alternate definition in
A.6.1.2140 REPEAT.
FOO
S" ]" EVALUATE
;
FOO
will leave the system in compilation state. Similarly, after
LOADing a block containing ], the system
will be in compilation state.
Note that ] does not affect the parse area and that the
only effect that : has on the parse area is to parse a
word. This entitles a program to use these words to set the
state with known side-effects on the parse area. For example:
: NOP
: POSTPONE ; IMMEDIATE
;
NOP ALIGN NOP ALIGNED
Some non-compliant systems have ] invoke a
compiler loop in addition to setting STATE. Such a
system would inappropriately attempt to compile the second
use of NOP.
XYZ
)
)
WORD COUNT TYPE
; IMMEDIATE
This works fine when used in a line like:
.( HELLO) 5 .
but consider what happens if the user enters an empty
string:
.( ) 5 .
The definition of .( shown above would treat the
) as a leading delimiter, skip it, and continue
consuming characters until it located another )
that followed a non-) character, or until the
parse area was empty. In the example shown, the
5 .
would be treated as part of the string to be printed.
With PARSE, we could write a correct definition of
.(:
: .(
[CHAR] )
PARSE TYPE
; IMMEDIATE
This definition avoids the "empty string" anomaly.
SAVE-
INPUT
and RESTORE-INPUT are called with the same input source
in effect.
In the above examples, the EVALUATE phrase could have
been replaced by a phrase involving INCLUDE-FILE
and the same rules would apply.
The standard does not specify what happens if a program
violates the above rules. A Standard System might check for
the violation and return an exception indication from
RESTORE-INPUT, or it might fail in an unpredictable
way.
The return value from RESTORE-INPUT is primarily
intended to report the case where the program attempts to
restore the position of an input source whose position cannot
be restored. The keyboard might be such an input source.
Nesting of SAVE-INPUT and RESTORE-INPUT is
allowed. For example, the following situation works as
expected:
| Input Source | possible stack values | |||
| block | >IN @ | BLK @ | 2 | |
| EVALUATE | >IN @ | 1 | ||
| keyboard | >IN @ | 1 | ||
| text file | >IN @ | lo-pos | hi-pos | 3 |
33000 32000 34000 WITHIN
The above implementation returns false for that test,
even though the unsigned number 33000 is clearly within the
range {{32000 ... 34000}}.
The problem is that, in the incorrect implementation, the
signed comparison < gives the wrong answer when 32000
is compared to 33000, because when those numbers are treated
as signed numbers, 33000 is treated as negative 32536, while
32000 remains positive.
Replacing < with U< in the above implementation
makes it work with unsigned numbers, but causes problems with
certain signed number ranges; in particular, the test:
2xxx deal
with cell pairs, where the relationship between the cells is
unspecified. They may be two-vectors, double-length numbers, or
any pair of cells that it is convenient to manipulate together.
Dxxx deal
specifically with double-length integers.
Mxxx deal with
some combination of single and double integers. The order in
which these appear on the stack is determined by long-standing
common practice.
setjmp() and longjmp(), and LISP's
CATCH and THROW. In the Forth context, THROW
may be described as a "multi-level EXIT", with
CATCH marking a location to which a THROW may return.
Several similar Forth "multi-level EXIT"
exception-handling schemes have been described and used in past years.
It is not possible to implement such a scheme using only standard words
(other than CATCH and THROW), because there is no portable
way to "unwind" the return stack to a predetermined place.
THROW also provides a convenient implementation technique for
the standard words ABORT and ABORT", allowing an
application to define, through the use of CATCH, the behavior
in the event of a system ABORT.
CATCH and THROW provide a convenient way for an
implementation to "clean up" the state of open files if an
exception occurs during the text interpretation of a file with
INCLUDE-FILE. The implementation of
INCLUDE-FILE may guard (with CATCH) the word
that performs the text interpretation, and if CATCH returns
an exception code, the file may be closed and the exception
reTHROWn so that the files being included at an outer nesting
level may be closed also. Note that the standard allows, but does not
require, INCLUDE-FILE to close its open files if an
exception occurs. However, it does require INCLUDE-FILE
to unnest the input source specification if an exception is
THROWn.
FIELD: definition.
FIELD: and
+FIELD) are defined so they can be used by both
schools. Compatibility between the two schools comes from
defining a new stack item struct-sys, which is
implementation dependent and can be 0 or more cells.
The name first school would provide an address (addr)
as the struct-sys parameter, while the name last
school would defined struct-sys as being empty.
Executing the name of the data structure, returns the size of
the data structure. This allows the data stricture to be used
within another data structure:
FIELD:) are
aligning. This is intentional and allows for both uses.
The standard currently defines an aligned field defining
word for each of the standard data types:
Although this is a sufficient set, most systems provide
facilities to define field defining words for standard
data types.
BFIELD: | 1 byte (8 bit) field |
WFIELD: | 16 bit field |
LFIELD: | 32 bit field |
XFIELD: | 64 bit field |
| Word | Key | Word | Key | |
| K-F1 | F1 | K-LEFT | cursor left | |
| K-F2 | F2 | K-RIGHT | cursor right | |
| K-F3 | F3 | K-UP | cursor up | |
| K-F4 | F4 | K-DOWN | cursor down | |
| K-F5 | F5 | K-HOME | home or Pos1 | |
| K-F6 | F6 | K-END | End | |
| K-F7 | F7 | K-PRIOR | PgUp or Prior | |
| K-F8 | F8 | K-NEXT | PgDn or Next | |
| K-F9 | F9 | K-INSERT | Insert | |
| K-F10 | F10 | K-DELETE | Delete | |
| K-F11 | F11 | |||
| K-F12 | F12 | |||
| Word | Key |
| K-SHIFT-MASK | Shift |
| K-CTRL-MASK | Ctrl |
| K-ALT-MASK | Alt |
FIELD: words provide for different
alignment and size allocation.
The xFIELD: words could be defined as:
S" name1" S" name2" RENAME-FILE
" ...
The interpretation semantics for S" are intended to
provide a simple mechanism for entering a string in the
interpretation state. Since an implementation may choose to
provide only one buffer for interpreted strings, an
interpreted string is subject to being overwritten by the
next execution of S" in interpretation state. It is
intended that no standard words other than S" should
in themselves cause the interpreted string to be overwritten.
However, since words such as EVALUATE,
LOAD, INCLUDE-FILE and
INCLUDED can result in the interpretation of arbitrary
text, possibly including instances of S", the
interpreted string may be invalidated by some uses of these
words.
When the possibility of overwriting a string can arise, it is
prudent to copy the string to a "safe" buffer allocated by
the application.
filename
filename
E" (see 12.3.7 Text interpreter input number conversion). Consensus in the committee deemed
this form of floating-point input to be in more common use than
the alternative that would have a floating-point input mode that
would allow numbers with embedded decimal points to be treated
as floating-point numbers.
Although the format and precision of the significand and the format
and range of the exponent of a floating-point number are
implementation defined in Forth-2012, the Floating-Point
Extensions word set contains the words
DF@, SF@, DF!, and SF!
for fetching and storing double- and single-precision IEEE
floating-point-format numbers to memory. The IEEE floating-point
format is commonly used by numeric math co-processors and for
exchange of floating-point data between programs and systems.
r FCONSTANT name
:} notation is a compromise
to avoid name conflicts.
The notation provides for different kinds of local: those that are
initialized from the data stack at run-time, uninitialized locals, and
outputs. Initialized locals are separated from uninitialized locals by
`|'. The definition of locals is terminated by
`--' or `:}'.
All text between `--' and `:}' is ignored. This eases
documentation by allowing a complete stack comment in the locals definition.
The `|' (ASCII $7C) character is widely used as the
separator between local arguments and local values. Some implementations
have used `\' (ASCII $5C) or `¦' ($A6).
Systems are free to continue to provide these alternative separators.
However, only the recognition of the `|' separator is
mandatory. Therefore portable programs must use the `|'
separator.
A number of systems extend the locals notation in various ways. Some of
these extensions may emerge as common practice. This standard has reserved
the notation used by these extensions to avoid difficulties when porting
code to these systems. In particular local names ending in
`:' (colon),
`[' (open bracket), or
`^' (caret) are reserved.
END-CODE is interpreted.
Your balance at %time% on %date% is %currencyvalue%.
% is used as delimiters for the substitution name. The
text "currencyvalue", "date" and "time"
are text substitutions, where the replacement text is defined by
REPLACES:
Your balance at 10:25 on 15/Nov/2014 is %currencyvalue%.